How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog
April 25, 2026
In this post, I’ll iteratively optimize an implementation of matrix multiplication written in CUDA. This post is a recreation of Si Boehm’s excellent worklog, used here as a template to demonstrate Tufte-CSS features: side notes, margin notes, side figures, full-width figures, code blocks, and references. My goal is not to build a cuBLAS replacement, but to deeply understand the most important performance characteristics of the GPUs that are used for modern deep learning. This includes coalescing global memory accesses, shared memory caching and occupancy optimizations, among others.
Matrix multiplication on GPUs may currently be the most important algorithm
that exists, considering it makes up almost all the FLOPs during the training
and inference of large deep-learning models. So how much work is it to write a
performant CUDA SGEMM
SGEMM performs C = α·A·B + β·C at
single (32-bit) precision.
from scratch? I’ll start with a
naive kernel and apply optimizations step-by-step until we get within 95% (on
a good day) of the performance of NVIDIA’s closed-source cuBLAS:
| Kernel | GFLOPs/s | Performance vs. cuBLAS |
|---|---|---|
| 1: Naive | 309.0 | 1.3% |
| 2: GMEM Coalescing | 1,986.5 | 8.5% |
| 3: SMEM Caching | 2,980.3 | 12.8% |
| 4: 1D Blocktiling | 8,474.7 | 36.5% |
| 5: 2D Blocktiling | 15,971.7 | 68.7% |
| 6: Vectorized Mem | 18,237.3 | 78.4% |
| 9: Autotuning | 19,721.0 | 84.8% |
| 10: Warptiling | 21,779.3 | 93.7% |
| 0: cuBLAS | 23,249.6 | 100.0% |
Kernel 1: Naive Implementation
In the CUDA programming model, computation is ordered in a three-level hierarchy. Each invocation of a CUDA kernel creates a new grid, which consists of multiple blocks. Each block consists of up to 1024 individual threads. Threads in the same block have access to the same shared memory region (SMEM). Threads that are in the same block have access to the same shared memory region (SMEM).
The number of threads in a block is configurable, usually a multiple of 32. The number of blocks in a grid depends on the size of the data.
C by reading a row of A and a column
of B.
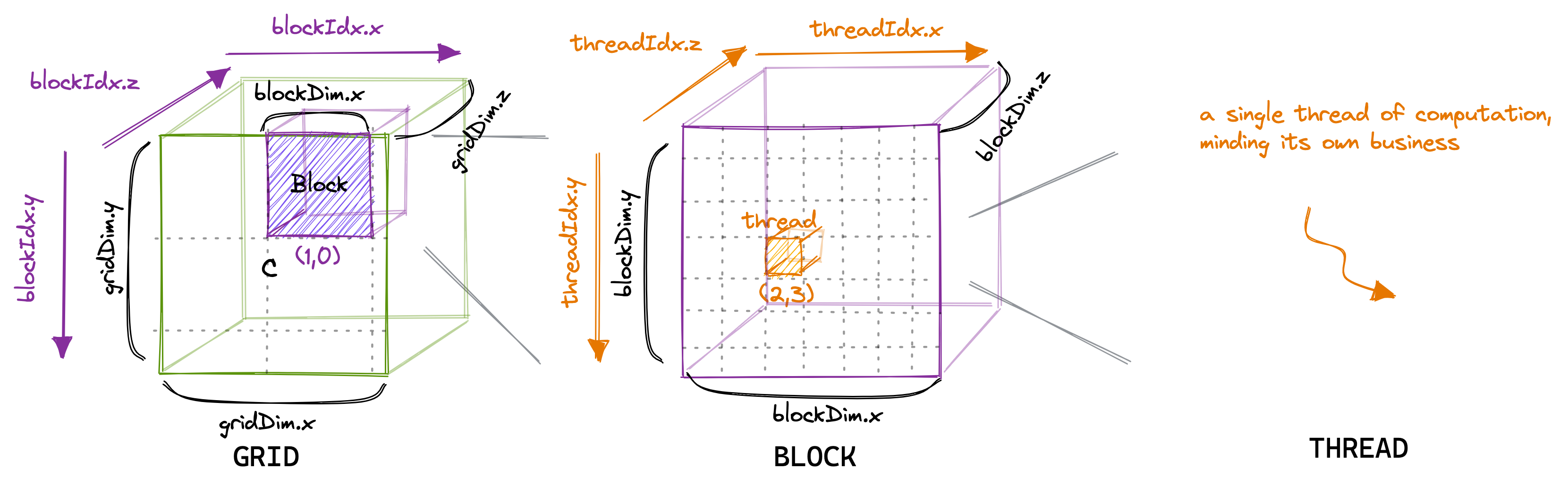
Let’s start by writing the most naive kernel: one thread per output entry of
C. The launch looks like this:
// create as many blocks as necessary to map all of C
dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32), 1);
// 32 * 32 = 1024 thread per block
dim3 blockDim(32, 32, 1);
sgemm_naive<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
The kernel body computes the dot product of one row of A with one column of
B:
__global__ void sgemm_naive(int M, int N, int K, float alpha,
const float *A, const float *B,
float beta, float *C) {
const uint x = blockIdx.x * blockDim.x + threadIdx.x;
const uint y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < M && y < N) {
float tmp = 0.0;
for (int i = 0; i < K; ++i) {
tmp += A[x * K + i] * B[i * N + y];
}
C[x * N + y] = alpha * tmp + beta * C[x * N + y];
}
}
When I run this kernel on an A6000 GPU it achieves ~300 GFLOPs when
multiplying two 4092×4092 float32 matrices.
For two 4092²
matrices, total FLOPs = 2·4092³ + 4092² ≈ 137 GFLOP. The memory traffic is
dominated by repeatedly reloading the same row/column from global memory:
about 548 GB of traffic against a peak bandwidth of 768 GB/s.
We can do much better.
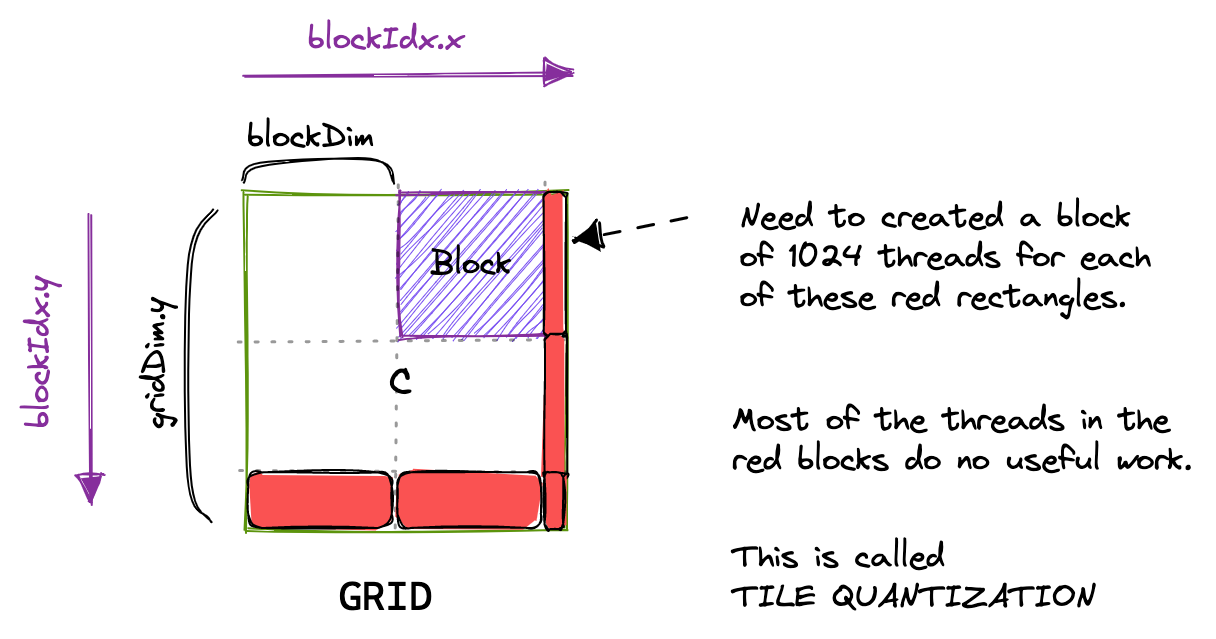 Tile quantization: when the matrix dimension isn’t a multiple of the tile size, the last row/column of tiles does partially wasted work.
Tile quantization: when the matrix dimension isn’t a multiple of the tile size, the last row/column of tiles does partially wasted work.
Kernel 2: Global Memory Coalescing
Threads with neighbouring threadId are grouped into warps of 32. A warp is
the unit of scheduling on the GPU; sequential memory accesses by threads in
the same warp can be coalesced into a single 32-byte memory transaction.
The naive kernel maps (threadIdx.x, threadIdx.y) to (x, y) such that
neighbouring threads in a warp end up reading from different rows of A —
which prevents coalescing. Swapping the assignment fixes this:
const int x = blockIdx.x * BLOCKSIZE + (threadIdx.x / BLOCKSIZE);
const int y = blockIdx.y * BLOCKSIZE + (threadIdx.x % BLOCKSIZE);
if (x < M && y < N) {
float tmp = 0.0;
for (int i = 0; i < K; ++i) {
tmp += A[x * K + i] * B[i * N + y];
}
C[x * N + y] = alpha * tmp + beta * C[x * N + y];
}
Memory throughput jumps from 15 GB/s to 110 GB/s, and performance reaches ~2000 GFLOPs.
Kernel 3: Shared Memory Cache-Blocking
Each block has access to a small chunk of fast on-chip shared memory (SMEM):
on the A6000, up to 48 KB per block.
On Volta, SMEM provides
~12,080 GiB/s of bandwidth versus ~750 GB/s for global memory — a 16×
difference.
The next optimization is to cache tiles of A
and B in SMEM and reuse them across many threads:
BLOCKSIZE×BLOCKSIZE tile of A and B into shared
memory, then every thread in the block performs its dot-product against the
shared tiles.
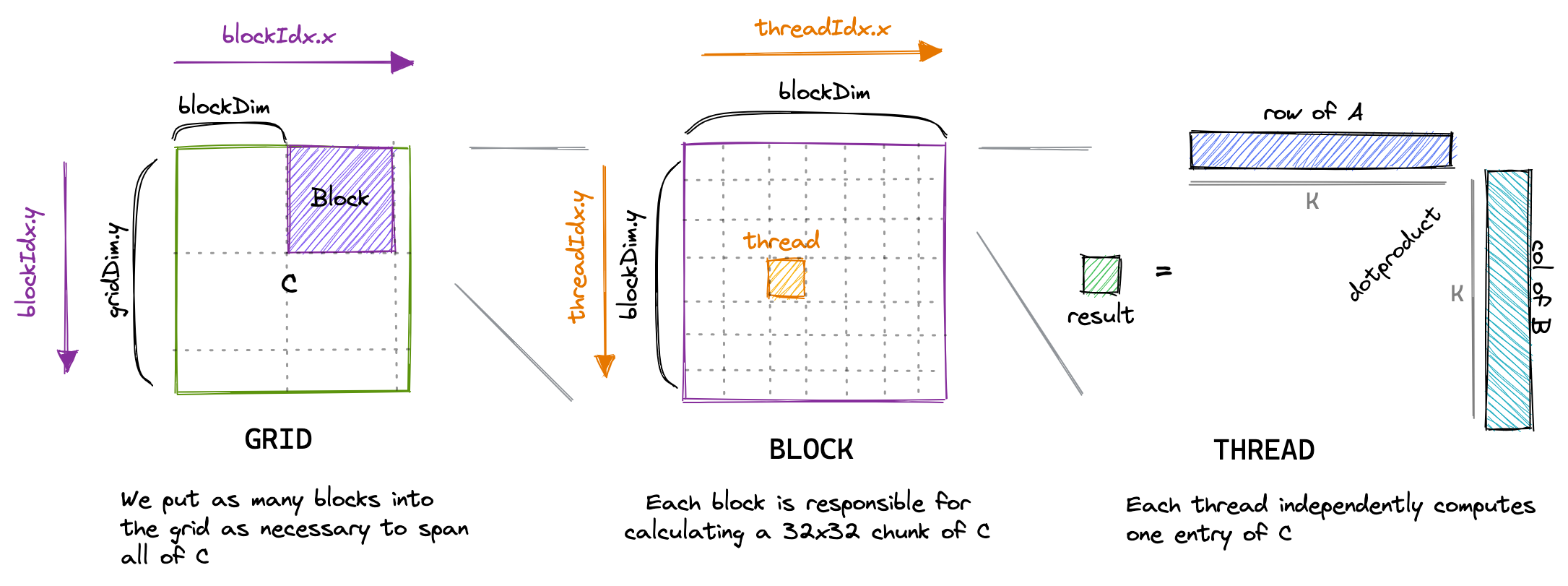
A += cRow * BLOCKSIZE * K;
B += cCol * BLOCKSIZE;
C += cRow * BLOCKSIZE * N + cCol * BLOCKSIZE;
float tmp = 0.0;
for (int bkIdx = 0; bkIdx < K; bkIdx += BLOCKSIZE) {
As[threadRow * BLOCKSIZE + threadCol] =
A[threadRow * K + threadCol];
Bs[threadRow * BLOCKSIZE + threadCol] =
B[threadRow * N + threadCol];
__syncthreads();
A += BLOCKSIZE;
B += BLOCKSIZE * N;
for (int dotIdx = 0; dotIdx < BLOCKSIZE; ++dotIdx) {
tmp += As[threadRow * BLOCKSIZE + dotIdx] *
Bs[dotIdx * BLOCKSIZE + threadCol];
}
__syncthreads();
}
This kernel achieves ~2200 GFLOPs, a 50% improvement over the previous version. We’re still bottlenecked on memory — but now on SMEM bandwidth, not GMEM.

Kernel 4: 1D Blocktiling
Computing multiple C entries per thread allows us to perform more of the
work in registers, where bandwidth is effectively unlimited:
float threadResults[TM] = {0.0};
for (uint bkIdx = 0; bkIdx < K; bkIdx += BK) {
As[innerRowA * BK + innerColA] = A[innerRowA * K + innerColA];
Bs[innerRowB * BN + innerColB] = B[innerRowB * N + innerColB];
__syncthreads();
A += BK;
B += BK * N;
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) {
float Btmp = Bs[dotIdx * BN + threadCol];
for (uint resIdx = 0; resIdx < TM; ++resIdx) {
threadResults[resIdx] +=
As[(threadRow * TM + resIdx) * BK + dotIdx] * Btmp;
}
}
__syncthreads();
}
This kernel achieves ~8600 GFLOPs, 2.2× faster than Kernel 3.
Kernel 5: 2D Blocktiling
Now compute an 8×8 grid per thread instead of a column. Sharing more inputs
across the per-thread grid increases arithmetic intensity:
float threadResults[TM * TN] = {0.0};
float regM[TM] = {0.0};
float regN[TN] = {0.0};
for (uint bkIdx = 0; bkIdx < K; bkIdx += BK) {
// ... cooperative GMEM → SMEM loads ...
__syncthreads();
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) {
for (uint i = 0; i < TM; ++i)
regM[i] = As[(threadRow * TM + i) * BK + dotIdx];
for (uint i = 0; i < TN; ++i)
regN[i] = Bs[dotIdx * BN + threadCol * TN + i];
for (uint m = 0; m < TM; ++m)
for (uint n = 0; n < TN; ++n)
threadResults[m * TN + n] += regM[m] * regN[n];
}
__syncthreads();
}
Result: ~16 TFLOPs, another 2× improvement.
Kernel 6: Vectorized Memory Access
Two tweaks: transpose As during the GMEM→SMEM copy so we can issue 128-bit
SMEM loads (LDS.128); use float4 for global loads.
float4 tmp =
reinterpret_cast<float4 *>(&A[innerRowA * K + innerColA * 4])[0];
// transpose A during GMEM → SMEM transfer
As[(innerColA * 4 + 0) * BM + innerRowA] = tmp.x;
As[(innerColA * 4 + 1) * BM + innerRowA] = tmp.y;
As[(innerColA * 4 + 2) * BM + innerRowA] = tmp.z;
As[(innerColA * 4 + 3) * BM + innerRowA] = tmp.w;
reinterpret_cast is purely a promise to the compiler
that the pointer is 128-bit aligned — it doesn’t generate any
instructions.GMEM loads upgrade from LDG.E (32 bits) to LDG.E.128 (128 bits), giving
~3% additional headroom for ~19 TFLOPs.
Kernel 9: Autotuning
The optimal (BM, BN, BK, TM, TN) parameters vary across GPU models. Sweeping
the parameter space with a small autotuner picks up another few percent — on
the A6000, BM=BN=128, BK=16, TM=TN=8 reaches 20 TFLOPs.
Kernel 10: Warptiling
Adding a warp level to the tiling hierarchy makes all three levels of parallelism explicit: blocks → warps → threads.
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) {
// load WMITER × TM A-fragments and WNITER × TN B-fragments into regs
// outer-product accumulate into threadResults[]
}
Different warps execute on different schedulers, SMEM bank conflicts only matter within-warp, and register caching wins more locality. Result: 21.7 TFLOPs — 93.7% of cuBLAS.
Conclusion
Optimizing SGEMM iteratively is one of the best ways to deeply understand the performance characteristics of GPU hardware. There’s a clear power-law: roughly the first 80% comes from a handful of well-known optimizations, and the last 15% requires a lot more work — autotuning, warptiling, and careful attention to instruction mix.
References
- Si Boehm. How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog. 2022. https://siboehm.com/articles/22/CUDA-MMM
- NVIDIA. CUDA C++ Programming Guide. https://docs.nvidia.com/cuda/cuda-c-programming-guide/
- NVIDIA. CUDA C++ Best Practices Guide. https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/
- NVIDIA. Kernel Profiling Guide (Nsight Compute). https://docs.nvidia.com/nsight-compute/ProfilingGuide/
- Vasily Volkov. Understanding Latency Hiding on GPUs. PhD thesis, UC Berkeley, 2016.
- NVIDIA. CUTLASS: Fast Linear Algebra in CUDA C++. https://github.com/NVIDIA/cutlass
- Source code for this post: github.com/siboehm/SGEMM_CUDA
Tags: cuda, gpu, performance, matmul